Recognize 2D objects at any location¶
This experiment shows how "location" might work. It shows how a network of cells can infer objects at any location if:
- You compute locations using path integration. You get a location by combining a previous location and a motor command.
- You can do path integration on unions of location SDRs.
We introduce a "location layer". Here are some neurons from the location layer:
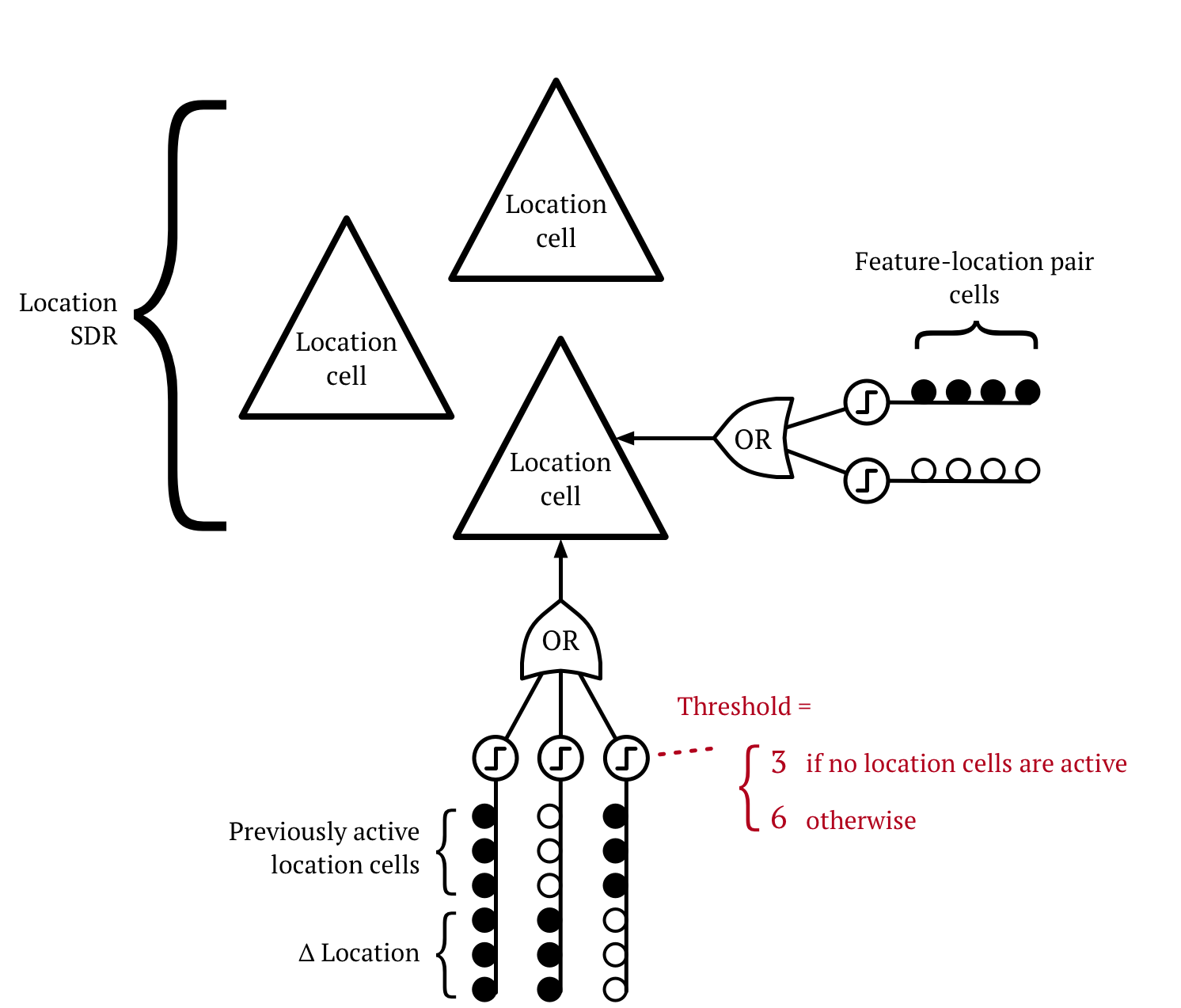
The actual thresholds might be higher. The "3" and "6" are for illustrative purposes.
Location SDRs and motor commands are related by motor commands (a.k.a. "deltas").
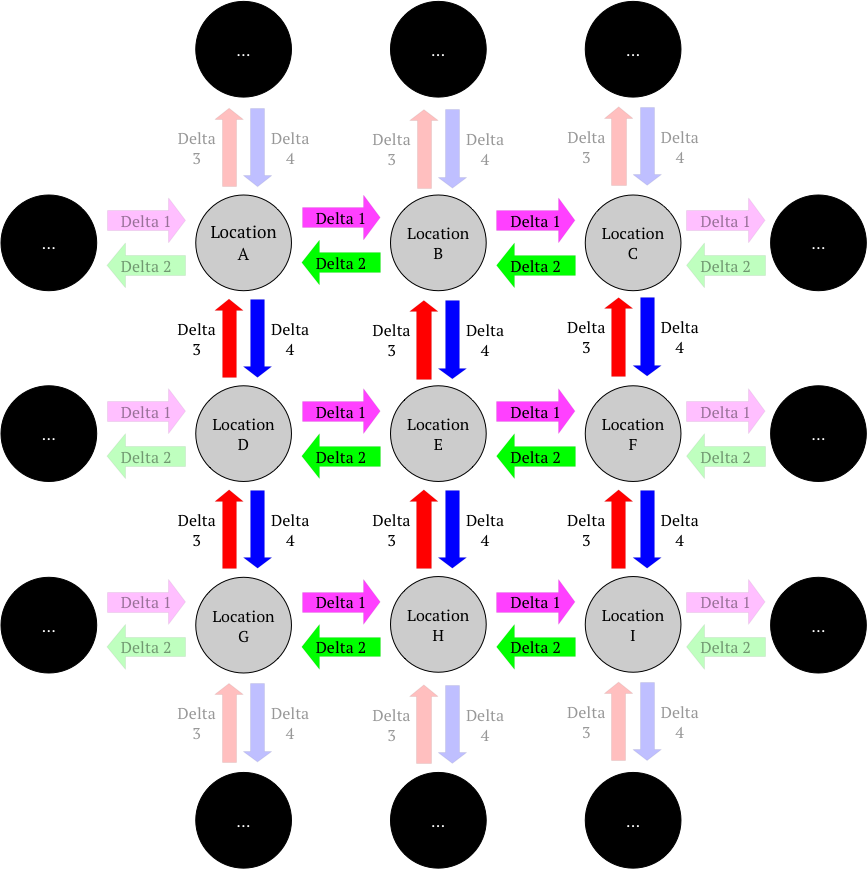
These locations form a reusable "space".
In this experiment, we train the location layer with proprioceptive input. Then we disable this proprioceptive input when we want to infer an object.
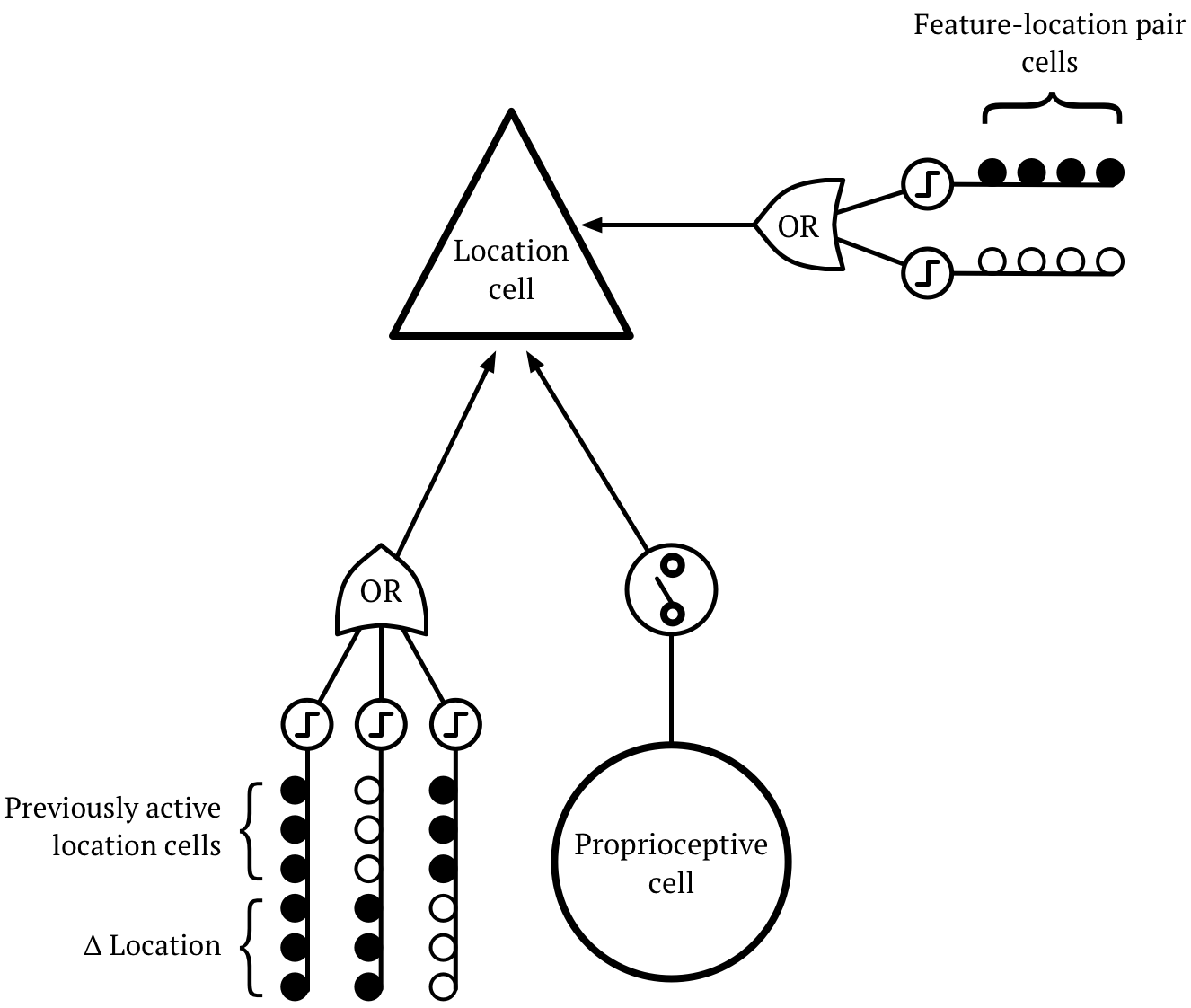
This is pretty elaborate. There are other ways to implement this location layer, and there are ways to train it that don't involve a sometimes-enabled proprioceptive input. The point of this experiment is to show that this layer can in principle be implemented, and that it solves a lot of "egocentric vs. allocentric" problems.
We take this "location layer" and we add it to the existing two-layer network which learns objects as sets of feature-location pairs.
This new three-layer network can infer objects no matter where the objects are placed in egocentric space.
First, let's look at what happens when the objects are placed in the same egocentric position where they were learned.
import htmresearchviz0.IPython_support as viz
viz.init_notebook_mode()
with open("logs/infer-no-location.csv", "r") as fileIn:
viz.printSingleLayer2DExperiment(fileIn.read())
Some explanation:
- This diagram shows three layers of cortex, three inputs, and the world (a.k.a. "egocentric space").
- For each input and layer, the diagram shows the active cells, and it shows a decoding of the active cells. The decodings are different for each input / layer.
- You can click through the diagram to see it update through time.
- After an object is inferred, we leap to a new object. These leaps are marked at the bottom as black lines in between the timestep circles.
- For each layer, you can hover over a cell to see its active synapses. This is especially useful on timesteps where there's a motor input. On these timesteps, try hovering over the cells in the location layer.
- In this recording, the "egocentric location input" is always empty. This input was used to train the location layer, and it's not needed any more, though it might be useful while learning new objects.
Here's a step-by-step explanation:
- Timestep 1:
- The network doesn't know the location, so Feature B bursts in the "feature-location pair layer".
- The object layer activates a union of all objects that have Feature B.
- Timestep 2:
- The location layer activates a union of locations where it has seen Feature B.
- The feature-location pair layer narrows down its union to just the active locations.
- Timestep 3:
- Nothing happens.
- Timestep 4:
- A "move left" motor command occurs.
- The location layer activates a new union of locations. This comes from shifting each location in the previous union to the left.
- Hover over cells in the location layer. You'll see that the cell was activated by the previous location and the motor command. In other words, this cell previously learned to recognize a "movement from a location", and this "movement from a location" happened.
- The feature-location pair layer receives Feature B (again) and activates the feature-location pair SDRs for each location in the location layer. It has only seen this feature at a subset of these locations, so the union is narrowed (i.e. it doesn't contain every location currently active in the location layer).
- Note that this narrowing could also occur due to apical input from the object layer.
- The object layer narrows down to only the objects that have two adjacent "B"s.
- Timestep 5:
- The location layer narrows. It essentially copies the information from the feature-location pair layer.
- Subsequent timesteps:
- This process continues. The network narrows down unions until it infers the object.
- This process is repeated for each object
Now let's scramble the objects and show that it can still infer them.
with open("logs/infer-shuffled-location.csv", "r") as fileIn:
viz.printSingleLayer2DExperiment(fileIn.read())
The same exact thing happens. The location layer always infers the location where it originally learned the object.
The downside of reusing locations¶
This algorithm doesn't always infer objects as fast as is theoretically possible. This experiment shows an example. We intentionally choose objects that will confuse the network.
Here we train a network on 3 objects, but we learn them each at the same point in the reusable "space". The lower-left point of each object is learned at the same location.
Then we try to infer an object. The network observes "A, right, B, right, C". In theory it should be able to infer the object after "A, right, B". But the union of objects has an additional "A" and a "B" at adjacent locations, so one of these objects is able to avoid getting removed, even though it doesn't contain "A, right, B". More sensations are needed before the object is inferred.
with open("logs/infer-not-perfect.csv", "r") as fileIn:
viz.printSingleLayer2DExperiment(fileIn.read())
This resolves itself if you step back and do it again: "A, right, B, left, A, right, B".
with open("logs/infer-recovery.csv", "r") as fileIn:
viz.printSingleLayer2DExperiment(fileIn.read())
Conclusion¶
Performing path integration on unions of location SDRs is a powerful technique.
If you reuse location SDRs for multiple objects, this can cause problems. A sensor can get confused when trying to infer an object with a sequence of movements and sensations. It's unclear how big a problem this is -- this issue would start to go away as you add more sensors.
If it is a big problem, then it would be better to use unique SDRs for each object, but somehow you'd need to be able to perform path integration on novel SDRs. In biology, grid cells seem to do exactly this. Maybe grid cells will solve everything.